Login to linux.cs.pdx.edu. The dig tool allows one to query the DNS hierarchy via the Linux command line. It allows one to specify a server to query, the type of record to query, and any queryopt(ions) including whether to use TCP or UDP for the query.
pdx.edu
Using ChatGPT, produce a dig command that queries PSU's local DNS server at 131.252.208.53 for the A record of www.pdx.edu using TCP.
- Take a screenshot of the prompt and the dig command produced.
Run the command to find the record. Then, use dig to do the same for the MX record of pdx.edu.
- Take a screenshot of the records returned for your lab notebook.
Using the IP addresses contained in these records, utilize IP address information services at https://www.iplocation.net/ to answer the following questions
- What cloud provider hosts the web site for www.pdx.edu?
- What cloud provider handles mail for pdx.edu?
mashimaro.cs.pdx.edu
Use dig to find the authoritative server (NS record type, AUTHORITY section response) for mashimaro.cs.pdx.edu and then query that server for the A record of mashimaro.cs.pdx.edu.
- Take a screenshot of the results for both records for your lab notebook.
Using ChatGPT or the man page for dig, find the query option that allows one to specify whether a query can recurse or whether it should be iterative.
Using a set of iterative queries, we will now simulate the operation of a local DNS server in resolving the name console.cloud.google.com. Start by running dig with no arguments to list all root DNS servers that have been hard-coded into the tool. Locate the IPv4 address (e.g. the A record) of the F root server.
Starting with the F root server, perform the iterative queries a local DNS server would perform on a lookup. In performing this sequence of queries, ensure the queries are iterative and use TCP. (MCECS networks block UDP DNS traffic). Ensure that you are traveling down the hierarchy with the servers being specified via the @. Ensure you use the appropriate DNS record type for specifying that the authoritative server should be returned.
- List all of the iterative dig commands performed for the lookup
- Take a screenshot of the results of the final query for your lab notebook.
Command preliminaries
First, perform the following commands and examine the output to understand what egrep, awk, and the pipes (|) are doing:
ls -l /dev
ls -l /dev | egrep vcs
ls -l /dev | egrep vcs | awk '{print $10}'
You can save the standard output of a command and use it in subsequent command-line arguments. One way is to save it to an environment variable using back-ticks `command` or $(command)
X=`ls -l /dev | egrep loop | awk '{print $10}'`
echo $X
X=$(ls -l /dev | egrep loop | awk '{print $10}')
echo $X
Then, you can use a for loop in bash to iterate over each value that is returned
for i in `echo $X` do file /dev/$i done
Aliases and reverse lookups
Using ChatGPT, produce a single command line with commands dig, egrep, and awk, to list all IPv4 addresses that espn.go.com points to.
- Take a screenshot of the prompt and the command produced
Run the command
- Take a screenshot of its results for your lab notebook
Find the flag for dig that allows one to perform reverse lookups on IPv4 addresses. Given the flag and the shell tutorial above, take that list of addresses and create a single for loop in the shell that iterates over the list and performs a reverse lookup of each IP address to find each address's associated DNS name. As with the previous step, pipe the output of the for loop to egrep and awk so that the output consists only of the DNS names.
- Take a screenshot of the command and its results for your lab notebook
Command preliminaries
Ranges in the shell can be specified via { } notation. Perform the following two commands to see how it works.
echo {0..2}{0..9}
for i in {1..20}
do
echo $i
done
Using a for loop, perform a reverse DNS lookup for each IP address on the 131.252.220.0/24 subnet. Note that some addresses on the subnet do not have names bound to them and will not return a record. Take the output of the loop and pipe it to egrep and awk to list just the names of the hosts, then redirect the final output to a file called 220hosts.txt, using the > character to perform output redirection to a file.
Within the range of hosts is a set of car manufacturer names. Using the head and tail commands, craft a command in the format below that returns their names.
cat 220hosts.txt | head -<number_of_lines_1> | tail -<number_of_lines_2>
- Take a screenshot of the results in your lab notebook
Content distribution networks (CDNs), covered later in this course, are a way of forward-deploying content to locations that are close to those who need access to it. Such networks can be implemented using DNS by replicating content across multiple servers and then having the authoritative DNS server for the site point resolutions to the replica nearest to the user.
To show how this is done, we will use dig to resolve www.google.com from different local name servers in order to see how resolution differs from different locations. After each step, answer the questions in your lab notebook.
Visit https://www.iplocation.net/ and look up the geographical location of the following DNS servers: 131.252.208.53 and 198.82.247.66.
- What geographic locations do ipinfo.io and DB-IP return?
Then, using dig, resolve www.google.com from each of the DNS servers. As Google forward deploys its web content close to its users, its name will resolve differently in different geographic locations.
dig @<DNS_server_IP> www.google.com- Record one address for www.google.com from each result for your lab notebook.
Go back to https://www.iplocation.net/ and look up the geographical location of the two IP addresses you recorded.
- What are the geographic coordinates of each DNS server and the IP address it resolves for www.google.com?
You should see that the IP addresses that are resolved reside geographically close to the DNS servers used to resolve them.
Perform a traceroute to all 4 IP addresses (131.252.208.53, 198.82.247.66, and the two IP addresses www.google.com resolves to) from a machine on the PSU network (e.g. linux.cs.pdx.edu).
- Take a screenshot of the results for your lab notebook.
In this lab, you will familiarize yourself with wireshark to capture and analyze packets. Begin by using RDP to bring up a graphical desktop session on your Linux VM in the cloud. Within the session, launch a terminal.
Then, install wireshark
sudo apt update sudo apt install wireshark -y
Allow the root user to bring up a graphical program via:
xhost si:localuser:root
Then launch Wireshark as the administrator account.
sudo wireshark
In a terminal, using commands from prior labs, find the addresses and interfaces on the VM. Make a note of:
- The IP address of the VM
- The name of the local virtual ethernet interface
- The IP address of the default router
Within wireshark, find the Capture options and use a "Capture Filter" to specify icmp (the protocol used by the ping command)
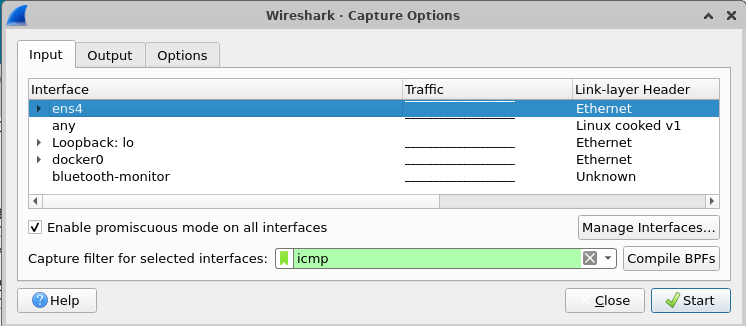
- Select your VM's virtual ethernet interface, then begin a capture
In a separate terminal send 3 ping messages to Google's web site
ping -c 3 www.google.comClick on the first packet in the top window of the wireshark UI. Then, in the middle window, expand the data-link layer packet and click on the destination hardware addresses. See which bytes in the payload window this corresponds to.
- Take a screenshot of the bytes in the packet dump window as shown below
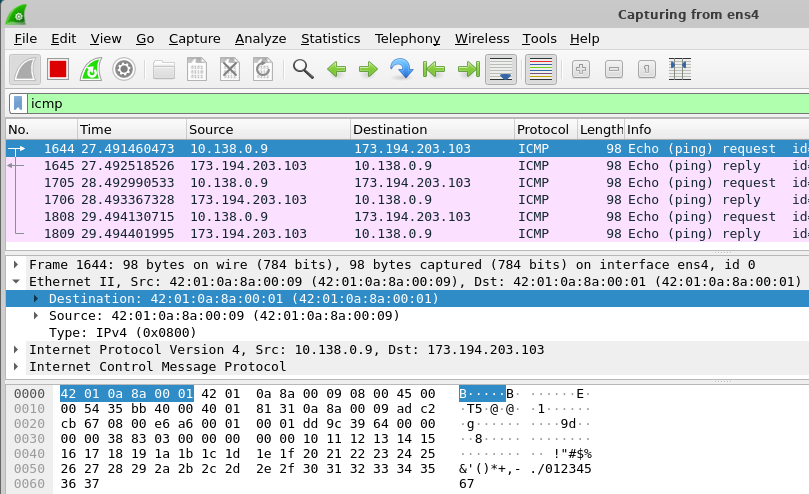
Answer the following question for your lab notebook.
- Does the destination MAC address correspond to an interface on the VM, an interface on the default router or an interface on Google's web site?
Click on the next packet in the trace.
- Does the destination MAC address correspond to an interface on the VM, an interface on the default router or an interface on Google's web site?
We will now perform packet analyses to recap the protocols you have learned. To begin with,
- Find the IP address of <
OdinId>.oregonctf.org, replacing <OdinId> with your OdinId
Before running our packet capture, we will use the shell to delete the ARP entry for the default router for the VM. Examine the output of the command below to see all of the entries in the table and their numeric IP addresses.
arp -anIn order to delete the ARP entry for the router, we simply run the command:
sudo arp -d <router_IP>Note that the entry is quickly regenerated the next time the machine has a packet to send. To see the deletion, we can run the arp -an command right after the delete command.
sudo arp -d <router_IP>; arp -anThe wireshark tool was derived from tcpdump, a command-line tool for collecting packet trace data. The trace files collected by both are compatible, allowing us to collect traces with tcpdump that we can then analyze within wireshark.
In a terminal, run the tcpdump command, specifying the name of the file to collect the packet trace in and keep the command running.
sudo tcpdump -w network_traceThen remove the default router's ARP entry and immediately retrieve http://<OdinId>.oregonctf.org (replacing <OdinId> with your Odin Id).
sudo arp -d <router_IP>; wget http://<OdinId>.oregonctf.orgBack in the window running tcpdump, type Ctrl+c to terminate the packet trace collection..
Launch wireshark. Under "File", open the packet trace file collected. Within the display filter interface, apply the following filter (substituting the appropriate values), in order to show all ARP, DNS, and HTTP traffic, along with any traffic to the IP address of the web site.
arp or dns or http or ip.addr==<oregonctf_IP>- Take a screenshot of the all of the packets returned within Wireshark that includes their packet numbers
ARP
- What packet numbers in the trace are the result of the VM attempting to get the hardware address of the default router?
- What is this hardware address?
DNS
- What packet numbers in the trace correspond to the DNS request for the web site?
- What is the IP address of the local DNS server being queried?
TCP
- What packet numbers in the trace correspond to the initial TCP handshake for the web request?
- How long does it take to perform the initial TCP handshake?
HTTP
- What packet numbers in the trace correspond to the actual HTTP request and response?
- How long does it take to process the HTTP request after the handshake?
Exit out of your RDP session, then stop the VM
gcloud compute instances stop <name_of_VM>